

Recently I read this tweet, underlining the issue of “tab hoarding”, which is the fact of having too many tabs opened within the browser without closing them regularly.
This issue impacts me: having more than 100 tabs opened simultaneously is not unusual. This is a problem for the following reasons:
- It’s a resource hog. This is why I installed a browser extension to suspend tabs automatically after a while without closing them ;
- It makes things hard to find. Ok, you keep a helpful tab opened, but when you have 100 tabs opened, it’s sometimes difficult to find it again as you only see the Favicon.
Reading this tweet, I said to myself: “Hmm, it would be good to get a kind of a searchable database of all visited URLs, where you can search by date, by keyword, regular expressions, etc.”.
In this post, I dive deeper into this idea.
Does it already exist?
Immediately we think about bookmarks. But bookmarks have their drawbacks: you still need to choose what to bookmark, and if you forget to bookmark a relevant webpage, you will lose it.
The advantage of storing all web pages visited is that you don’t have any more to add them manually: you can type some keywords to retrieve what you are looking for.
A browser extension that proposes a searchable database of strictly all web pages visited would solve the problem of “tab hoarding”, at least in my case. I would not be afraid to close my tabs since I can find them again easily.
Wait… Does a browser extension necessary?
After all, it is the browser’s job to do that, and we all know that each visited URL is kept somewhere as it is notably used during Forensic investigation. Could it be possible that I missed the feature of my dream in modern browsers?
Discovering the History of browsers
I felt completely retarded when I tried to access the History function of Chrome, Firefox and Brave browsers. It just works, and this feature has never been included in my working process.
What a shame seriously.
On Firefox, for instance, type Ctrl+H and you’ll see a nice sidebar showing the history, ordered by date (Today, Yesterday, Last 8 days, This month, etc.).
You can type some keywords, and it will immediately filter the list.
This is a nice start. But how does this search engine works?
History search with Firefox
On Firefox, the first question I had in mind was: “is the keyword searched in the URL or in the URL and in the webpage title”?
So I did a test. I created an HTML file called keyword1-keyword2.html and containing the following content:
<html>
<head>
<title>keyword3 keyword4</title>
</head>
<body>
Test
</body>
</html>I opened it in Firefox, watching the History. It appears well, and the title is displayed.
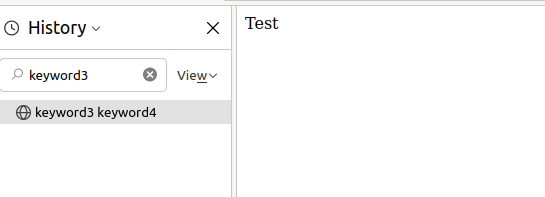
The page is still displayed if I type “keyword1” in the search field.
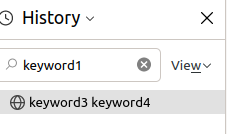
That’s nice. The search engine takes into account the Title and the URL in itself.
History search with Chrome
I did the same test with Chrome. It works the same.
Limitations of this feature
There are still many limits to the History feature. I noted several ones:
- With Firefox, when you search for a keyword, the visit date is not displayed. Not very practical. With Chrome, the date is displayed which is a bit easier.
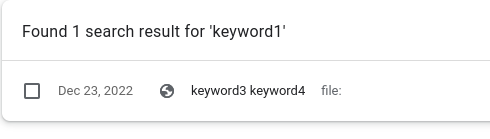
- With Chrome, the History cannot be opened in a sidebar apparently. It’s a full webpage opened in a new tab. The best way to circumvent that if you use History frequently might be to pin the tab, it will take lesser space so you don’t need to close it each time. If you press Ctrl-H a second time, it will not close the window but will focus on the pinned tab.
- The search field does not allow more complex requests on both browsers. You cannot, for instance, search for a keyword and a date. You cannot also negate a keyword (keyword1 -keyword2) like Google.
- The Web UI is average on both browsers. It could be a lot better. This is perfectly strange that browsers don’t show some love to this feature. Usage stats, likely, might drive this, this feature is probably not used by 99% of users.
Adding features with browser extensions
A quick search in browser extensions shows that many extensions are available to improve the history search page. I noticed tree of them on Firefox, which adds features to the native search:
- Regex History Filter: an extension to search the history using regular expressions.
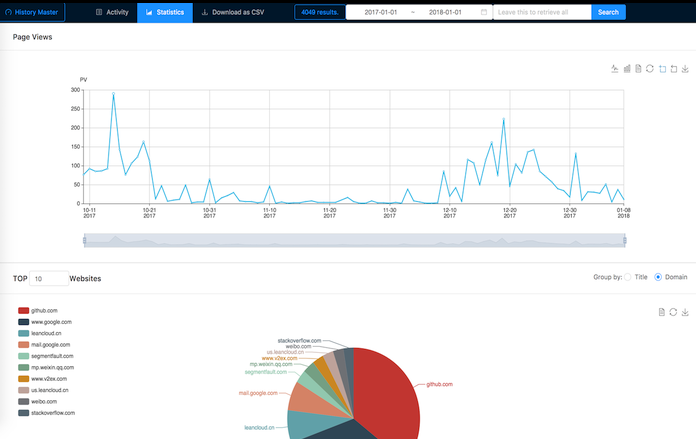
- History Master, which allows displaying statistics about your browsing habits.
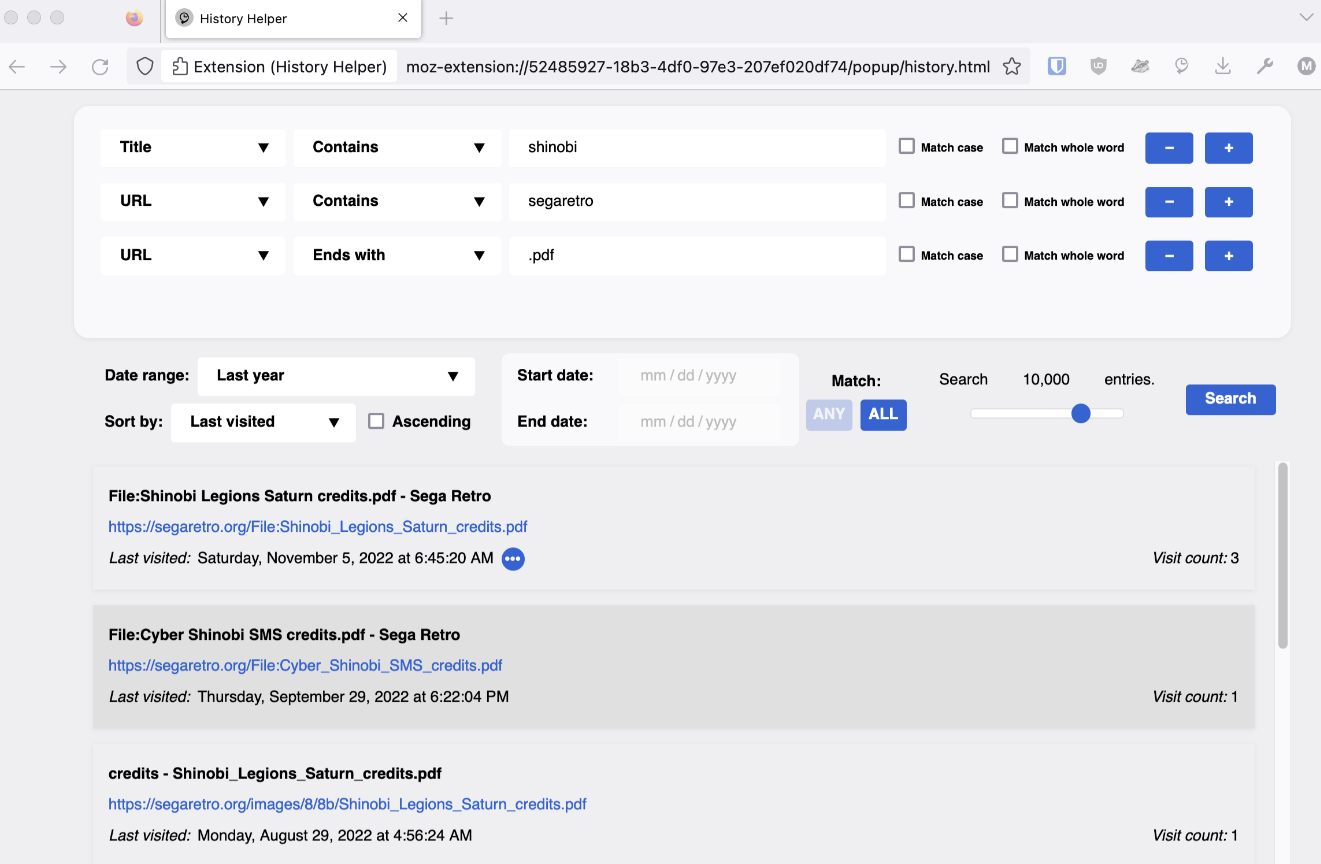
- History Helper: an extension to provide better filtering options. It allows you to search by title, URL and visit count, case sensitive or insensitive. It seems to be updated frequently but has only 7 users for now.
I didn’t test these extensions.
Is there a business opportunity?
We know at this stage that some extensions improve the features of the History of browsers. They don’t seem very popular or massively used: History Master – which looks great – has “only” 2002 users.
It seems there is not a big demand for these kinds of features.
However, it may be pushed further.
Accessing the database from the command line
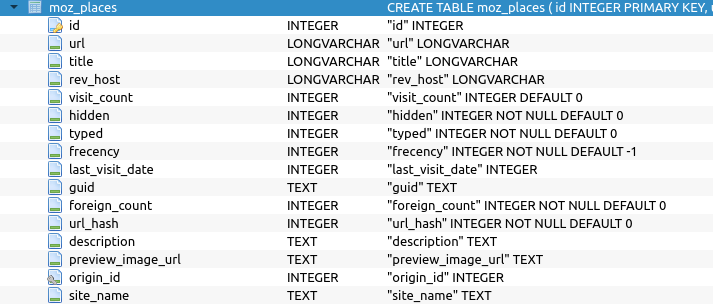
For Firefox, everything is stored in a SQLite database called places.db in your Firefox profile.
Within the moz_places table of this database, you’ll find some interesting information, like the URL and title of the visited page (obviously), but also the visit count, and if the URL has been typed in the address bar or if it has been visited by clicking a link. You also have a field called “preview_image_url” which is, I suppose, the address of the Favicon.
For Chrome, this is also a SQLite database contained in the directory ~/.config/google-chrome/Default/History.
It has a different structure but contains similar information.
What can be done with this data?
We can consider that what you browsed online in the past is like a “second brain”. We could imagine an application that takes your browsing history, gets the webpages, and ingests them regularly, to provide you with a search engine of all things you read in the past. It would be a “mini-internet” of what you have already seen.
Some potential use-cases:
- You are a journalist. You read many press articles every single day. You cannot remember everything about what you read. Now, let’s say you need to retrieve one article you have already seen about a person and a corruption story. You type the name of this person and the keyword “corrupt”, you get the article immediately.
- You are a developer. You know you have read a code snippet using a particular function. You type the name of this function, you get the result immediately.
I would be interested in such a product, and this would definitely tackle the “Tab hoarding” issue.
Technical approach
I don’t know which engine can grab HTML webpages and offer a ready-made efficient search engine.
Something like Open Semantic Search might be good, as it can ingest HTML files and have a good search engine.
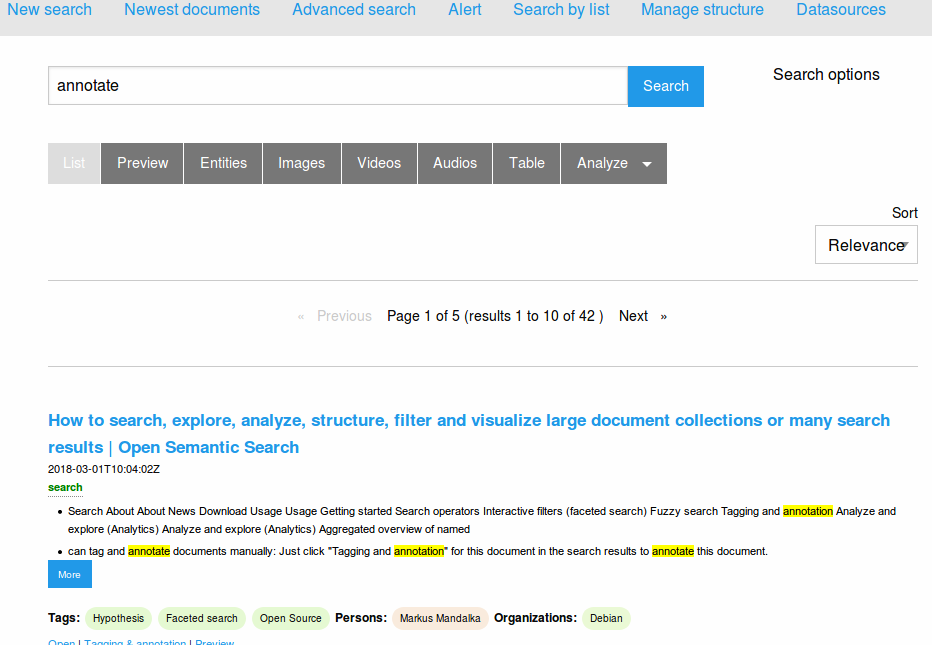
However, releasing it as a standalone application would be challenging as it’s based on Apache Solr.
A SaaS app would be more convenient, however, there will be privacy concerns.
Is there a market for that?
I don’t know if such a product can be financially sustainable. One major objection would be: “If I need information I consulted in the past, I just use Google”.
And it’s partly true.
If I take my own experience:
- Sometimes, I was not able to find again what I had read in the past, or it took a long time. It’s frequent.
- It may happen that the page disappears or has been changed.
The second point might be interesting, especially for journalists. As the history database is updated in real-time, it may allow building a product to keep automatically and immediately the page you read, to detect potential further changes.
It could even be an alert system: you visit a page on the date D1. Then you visit it again on the date D2. If there is a change, you will receive a notification.
I am sure there are some opportunities for exploiting these real-time databases.
I am keeping the idea in mind, and meanwhile, I will try to close my tabs: Ctrl+H is enough to find again a closed tab 😉
Leave a Reply